|
I'm using an acoustic model adapted to my voice, so I needed to record my own test sets. The first I recorded was a newswire test set (si_dt_s2, 207 utterances). 4.4% OOV at my 20K vocab, non-verbalized punctuation, single sentences. I recorded this set two separate times, once on the N800 and once using a desktop mic.
si_dt_s2 test set
si_dt_s2 test set, with my audio
In the second test set, I wanted email-like utterances. So I took 300 sentences out of the Enron corpus. 2.3% OOV at 20K vocab, non-verbalized punctuation, single sentences.
Enron test set
Enron test set, with my audio
For the third test set, I wanted SMS-like utterances. I couldn't find any decent SMS-text corpus, so I took 262 messages from the sent items of my phone. I did some manual cleanup, anonymizing, etc. 5.5% OOV at 20K vocab, verbalized punctuation, single and multiple sentences.
SMS test set
SMS test set, with my audio
| Amount of Adaptation Data |
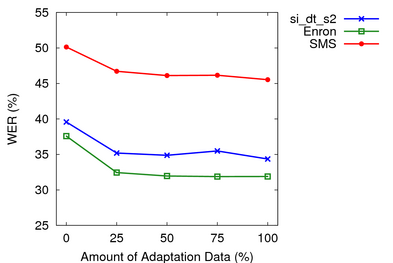
I recorded 600 total adaptation utterances and created adapted models using 25% - 100% of the data. For all three test sets, most of the gains were seen in the first 25% (150 utterances).
|

