|
On the WSJ 5K task, I saw a WER of around 8-9% for the 1-best Viterbi decoding result. Often many of the errors could be corrected by choosing other words in the recognizer's search space. I used a word confusion network (WCN) as the basis for a correction interface (similar to the interface by Ogata and Goto).
A word confusion network is a time-ordered sequence of clusters where each cluster contains competing words and their probabilities. The probabilities in a cluster sum to one. A WCN is constructed using the time-overlap of words in the recognizer's word lattice output. WCNs can contain a special *DELETE* word representing the hypothesis that a particular cluster generated no word output. The best recognition result is found by taking the highest probability hop in each cluster.

Example word confusion network, the best recognition result is "the cat sat".
The confusion network correction interface only has a limit amount of vertical screen space to display alternates for each cluster. I tested the effect such a limit has on the oracle WER (e.g. the best WER you could obtain using any path in the confusion network). One design choice is whether to include a *DELETE* word in every cluster (regardless of whether it was probable according to the WCN). I tested adding a *DELETE* hop to clusters which did not already have one. This has the effect of lowering the oracle WER even further as all insertion errors can be corrected.
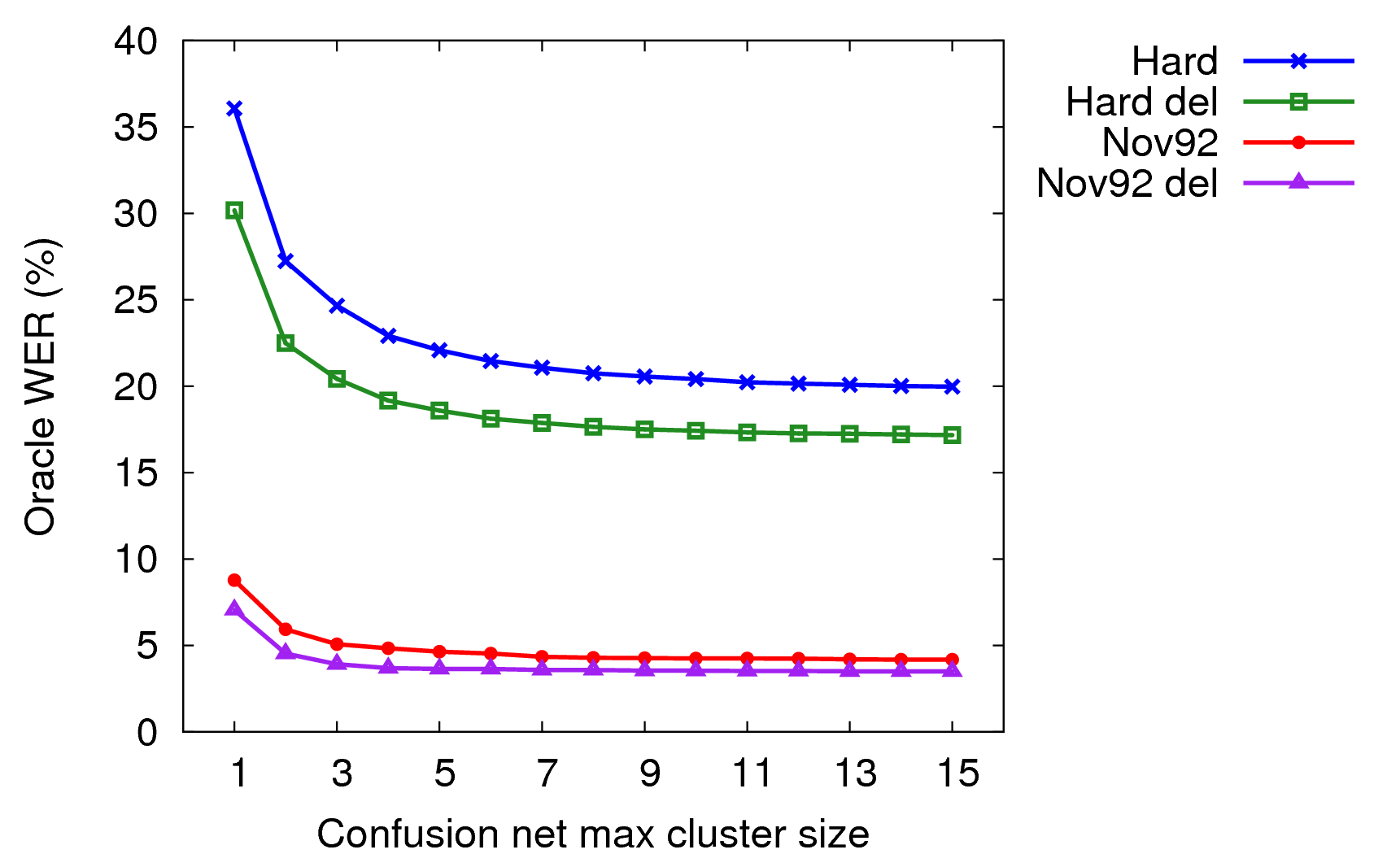
I tested this on a speaker-independent test set, Hard (wsj0 si_dt_jr, wsj1 si_dt_s2/sjm si_et_s2/sjm si_et_h1/wsj64k, 784 utts). I also tested it using my adapted acoustic model on Nov'92 (330 utts).
As can be seen in the graph above, gains levelled out after 8 or so alternates. For both test sets, the best path through the confusion network cut the WER in half compared to the original 1-best recognition result. But even for the easy Nov'92 task, there still is a residual level of error (around 4% WER) which will need correction by some method besides choosing from the confusion network alternatives.
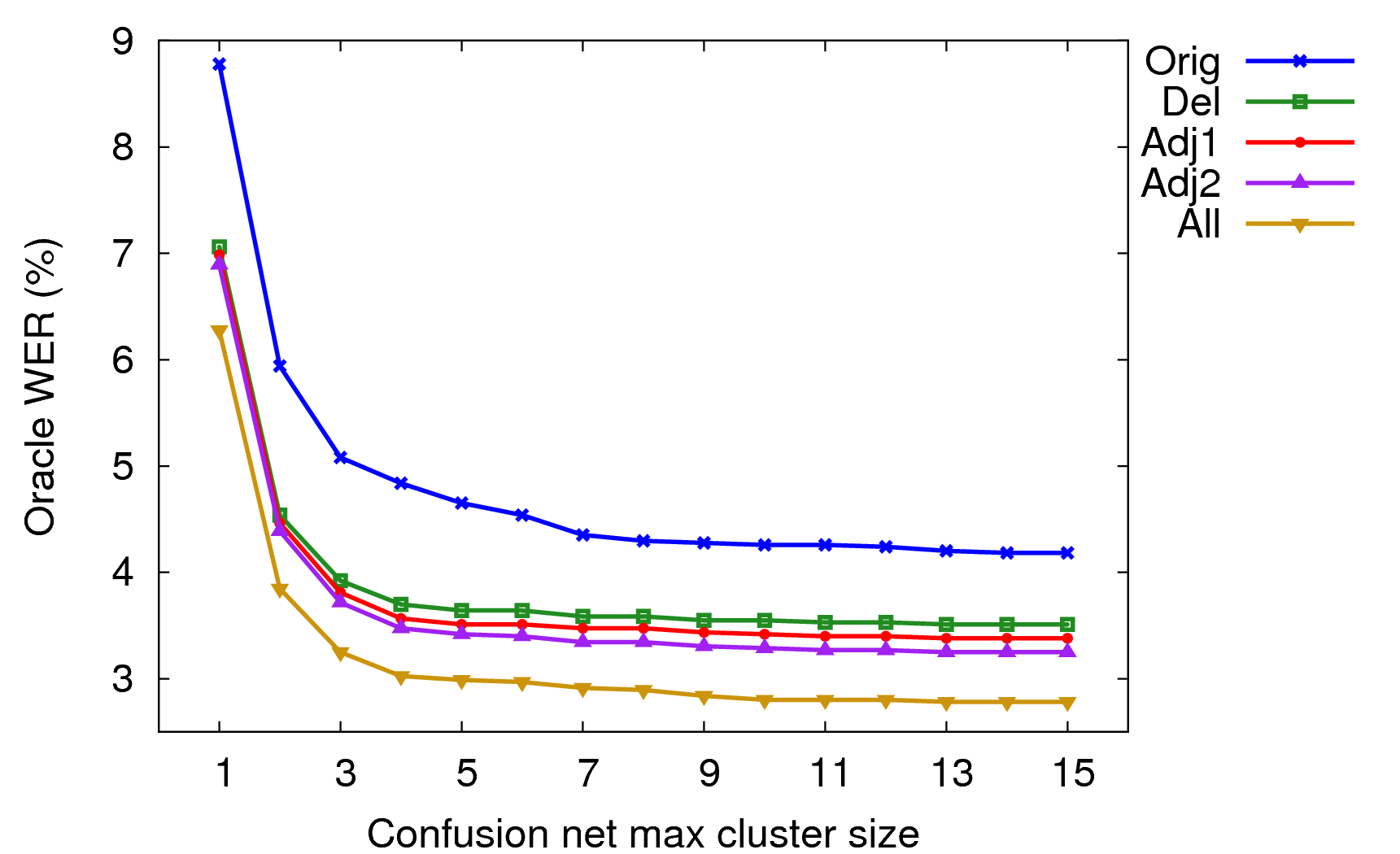
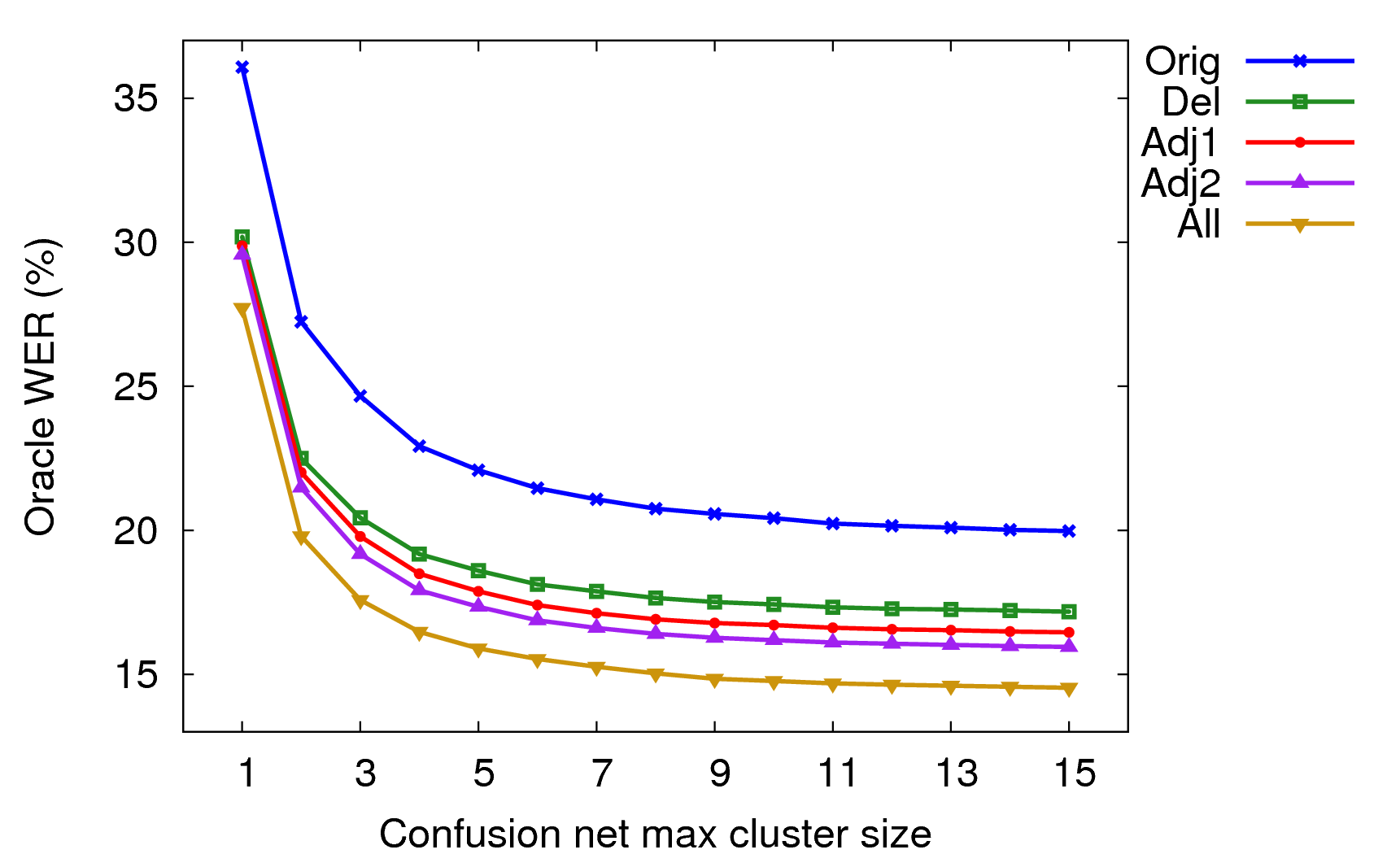
Another possible design choice would be to allow the user to copy words among the different confusion network clusters. This would allow correction of errors where the cluster itself did not have the correct word, but a neighbouring cluster did. In addition to always adding a *DELETE* hop, I measured the oracle WER assuming words could be taken from other clusters. I compared using the immediately adjacent clusters (adj1), the two cluster before and after (adj2), and using words from all clusters (all).
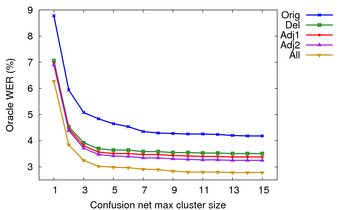
Oracle WER on Nov'92 allowing differing amounts of copying between clusters.
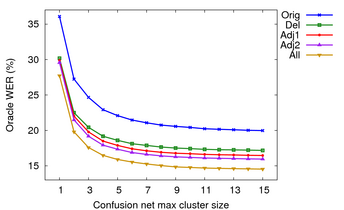
Oracle WER on Hard allowing differing amounts of copying between clusters.
As one would expect, allowing more and word word possibilities per cluster decreases the oracle WER. At a maximum cluster size of 6 on Nov'92, I found adding a *DELETE* hop to every cluster reduced oracle WER by 20% relative. Allowing selection of any word in the the entire WCN for any cluster reduced oracle WER by 35% relative. But assuming only adjacent clusters were used for copying, oracle WER was reduced by 25% relative.
|