The Nokia N800 has a built-in speakerphone type microphone. I doubt it would work well for speech recognition. The included plug-in lapel mic is better, but I wanted something noise cancelling with a boom mic. I used a Blueparrot B150 wireless bluetooth mic. Recording on the N800 is done via GStreamer (I couldn't get PortAudio to work on the N800) and was limited to 8kHz bandwidth.
N800's audio bandwidth limitation required me to downsample models trained using my CMU Sphinx WSJ training recipe. Experiments with the PocketSphinx decoder showed that a semi-continuous model provided the best speed with acceptable accuracy. I tried a HMM topology with 3-states instead of 5, but it was no faster and was less accurate.
Narrowband WSJ semi-continuous acoustic model
Model details and recognition results
| Recording Adaptation Data |
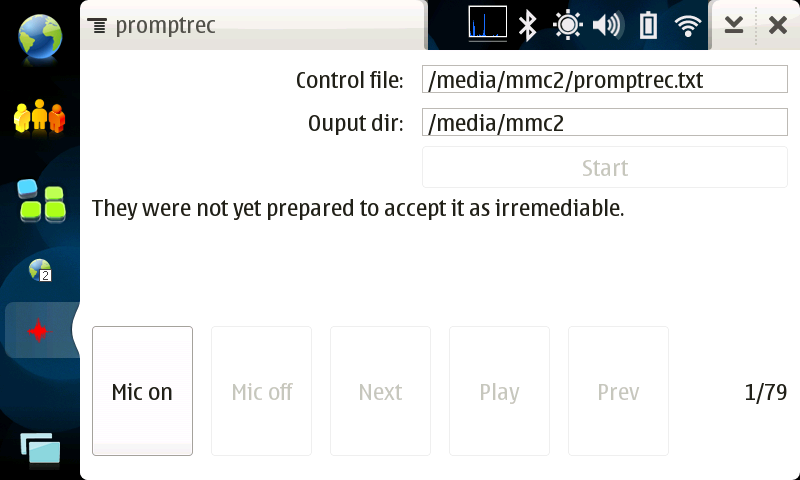
Adapting the WSJ acoustic model to your voice and microphone should improve recognition accuracy. I built a simple prompt recording application using GTK and GStreamer. It prompts users to speak a series of sentences, recording the raw 8kHz audio.
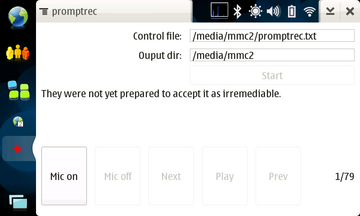
Screenshot of the PromptRec N800 application.
PromptRec Debian installer
PromptRec sources
Using PromptRec, I collected utterances on the N800 with my bluetooth mic. I wasn't sure how much I'd need, so I created a large set of 600 adaptation sentences using WSJ corpus adaptation utterances and TIMIT prompts. These were split into 6 control files for use with the PromptRec program.
WSJ/TIMIT adaptation set
WSJ/TIMIT adaptation set, with my audio
| Adapting the Acoustic Model |
I adapted the acoustic model using a 1-class MLLR transform of the means, followed by MAP adaptation of the mixture weights and means. I created adapted models using 25%, 50%, 75%, and 100% of my 600 utterance adaptation set. This was done on a desktop using utilities from SphinxTrain and Sphinx-3.
Sphinx adaptation kit
Semi-continuous model, adapted to me on 150 utterances
Semi-continuous model, adapted to me on 300 utterances
Semi-continuous model, adapted to me on 450 utterances
Semi-continuous model, adapted to me on 600 utterances
|